 Connect to data: Overview
Connect to data: Overview
 |  | | |  | |  |
- Completing the Quickstart guide is recommended.
Connecting to your data in Great Expectations is designed to be a painless process. Once you have defined your Datasources and Data Assets, you will have a consistent API for accessing and validating data on all kinds of source data systems such as SQL-type data sources, local and remote file stores, and in-memory data frames.
The connect to data process
Connecting to your data is built around the DatasourceProvides a standard API for accessing and interacting with data from a wide variety of source systems. object. A Datasource provides a standard API for accessing and interacting with data from a wide variety of source systems. This makes working with Datasources very convenient!

Behind the scenes, however, the Datasource is doing a lot of work for you. The Datasource provides an interface for an Execution EngineA system capable of processing data to compute Metrics. and possible external storage, and handles all the heavy lifting involved in communication between Great Expectations and your source data systems.
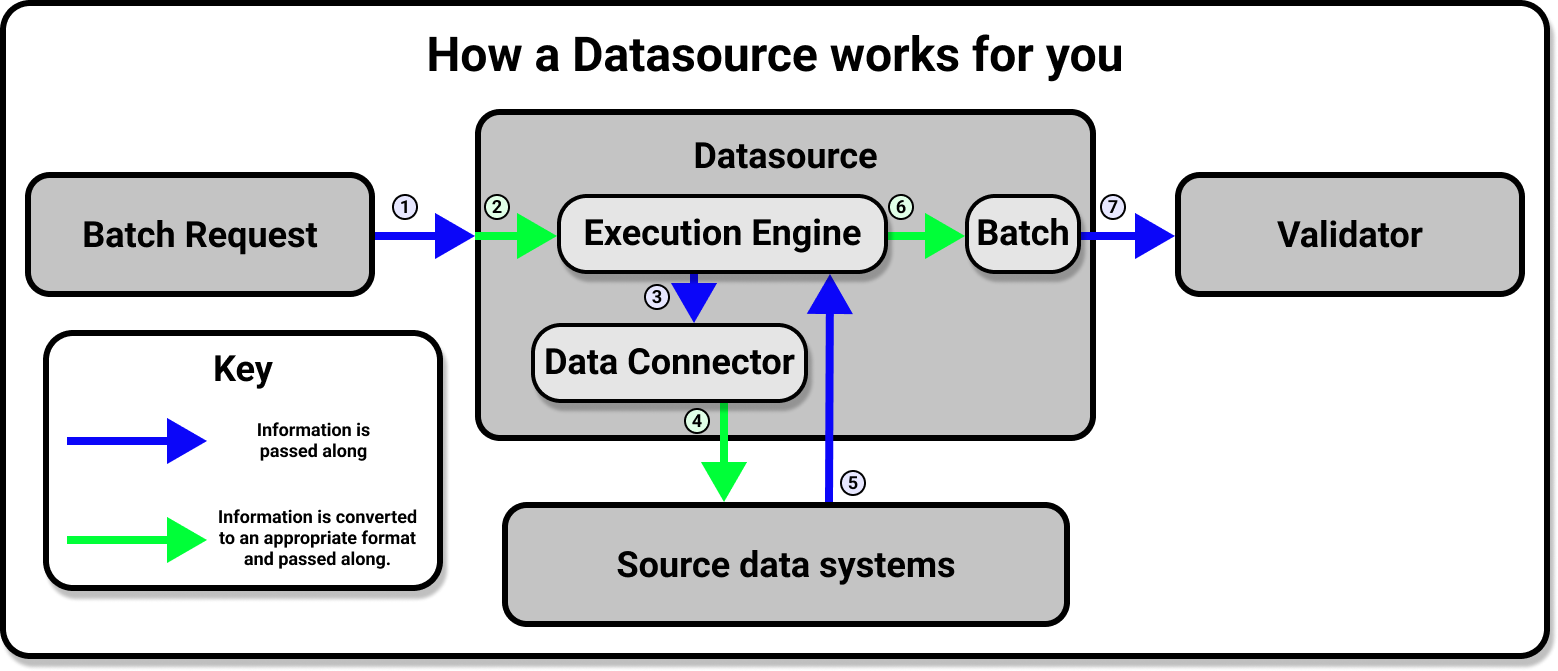
The majority of the work involved in connecting to data is a simple matter of adding a new Datasource to your Data ContextThe primary entry point for a Great Expectations deployment, with configurations and methods for all supporting components. according to the requirements of your underlying data system. Once your Datasource is configured you will only need to use the Datasource API to access and interact with your data, regardless of the original source system (or systems) that your data is stored in.
Configuring your Datasource
Because the underlying data systems are different, how you connect to each type of Datasource is slightly different. We have step by step how-to guides that cover many common cases, and core concepts documentation to help you with more complex scenarios. It is strongly advised that you find the guide that pertains to your use case and follow it. The following will give you a broad overview of what you will be doing regardless of what your underlying data systems are.
Datasource configurations can be written in Python using our Fluent Datasource API. Regardless of variations due to the underlying data systems, your Datasource's configuration will look roughly like this:
import great_expectations as gx
context = gx.get_context()
context.sources.add_pandas_filesystem(
name="my_pandas_datasource", base_directory=data_directory
)
Please note that this is just a broad outline of how to configure a datasource. You will find much more detailed examples in our documentation on how to connect to specific source data systems.
The name key will be the first you need to define. The name key can be anything you want, but it is best to use a descriptive name as you will use this to reference your Datasource in the future.
The add_<datasource> method will take Datasource-specific arguments used to configure it.
For example, the add_pandas_filesystem takes a base_directory argument in the example above while the
context.sources.add_postgres(name, ...) method takes a connection_string that is used to connect to the database.
Calling the add_<datasource> method on your context will run configuration checks.
For example, it will make sure the base_directory exists for the pandas_filesystem Datasource and the connection_string is valid for a SQL database.
These methods also persist your Datasource to the underlying storage. The storage depends on your Data ContextThe primary entry point for a Great Expectations deployment, with configurations and methods for all supporting components.. For a File Data Context the changes will be persisted to disk; for a Cloud Data Context the changes will be persisted to the cloud; for an Ephemeral Data Context the data will remain only in memory.
Accessing your Datasource from your Data Context
If you need to directly access your Datasource in the future, the context.datasources attribute of your Data Context will provide a convenient way to do so.
Here is how to view the configuration:
datasource = context.datasources["my_pandas_datasource"]
print(datasource)
Retrieving Batches of data with your Datasource
This is primarily done when running Profilers in the Create Expectation step, or when running Checkpoints in the Validate Data step, and will be covered in more detail in those sections of the documentation.
Wrapping up
With your Datasources defined, you will now have access to the data in your source systems from a single, consistent API. From here you will move on to the next step of working with Great Expectations: Create Expectations.